
프로젝트 개요
배경
흑백요리사라는 프로그램이 큰 인기를 끌면서 출연 셰프들의 식당 예약 수요가 급증해 여러 예약 서비스에 트래픽이 몰린다는 이슈를 접했습니다. 이를 계기로, 유연하고 확장성 있는 서비스를 클라우드 환경에서 제공하면 사용자 경험을 개선할 수 있겠다고 생각했습니다. 이에 클라우드 기술을 활용해 트래픽 증가에도 안정적으로 식당 예약 서비스를 운영할 수 있는 시스템을 구축해보고자 해당 프로젝트를 시작했습니다.
목표
- 트래픽 집중 예상 기능의 독립적 확장과 유지보수를 위해 MSA를 도입
- AWS ECS 기반 컨테이너 배포로 자동 확장과 트래픽 급증에 유연하게 대응
- 서비스별 최적 데이터베이스 선택으로 읽기/쓰기 성능 극대화
- AWS CloudFront와 CloudFront Functions로 글로벌 사용자에게 지연 시간 최소화 제공
- 애플리케이션 로그 수집 및 Slack 알림으로 신속한 문제 대응 체계 구축
팀원 구성
- 4명
- 백엔드: 고진혁, 박성은
- 프론트엔드: 이태현, 김지현
기술 스택
- 프론트엔드: React, JS, HTML, CSS
- 백엔드: Spring Boot, Python, PostreSQL, Docker
- 배포: Amazon Web Services
- 로그수집 및 에러로깅: OpenSearch, Kibana, FluentBit
- 협업: Jira, Github, Slack, Figma
주요 기여 내용
- 전체 서비스 Microservice Architecture로 설계 (1인 담당)
- AWS ECS(Elastic Container Service)를 활용한 서비스 배포
- AWS ECS를 이용하여 마이크로서비스를 효율적으로 배포하고 관리함으로써 높은 가용성과 확장성을 확보
- 개발한 애플리케이션에서 필요로 하는 환경변수를 AWS Systems Manager Parameter Store로 관리하고, 컨테이너 이미지를 ECR(Elastic Container Registry)에 저장하여 ECS 배포 시 활용하도록 설정
- AWS 각 인스턴스 별 필요한 보안그룹과 IAM Role 설정
- 각 마이크로서비스 SpringBoot로 개발 및 서비스별 읽기/쓰기 작업량에 최적화된 데이터베이스 설계
- Spring Boot를 사용해 마이크로 서비스 API 개발
- 각 마이크로서비스의 읽기/쓰기 작업량에 최적화된 데이터베이스를 선택하고 설계하여 시스템의 성능과 확장성을 극대화
- OpenSearch가 영구 저장소로 단독 사용하기에 부적합하다고 판단하여 DynamoDB와 DynamoDB Streams, Lambda를 도입하는 방향으로 설계
- VPC 내 Public Subent에 Bastion Host(EC2) 생성하여 SSH 터널링을 통한 데이터베이스 관리
- SSH 터널링을 통해 Private Subnet에 있는 데이터베이스에 안전하게 접근하도록 설정
- 관리자의 IP만 허용하는 보안 그룹 생성으로 보안 강화
- 멀티 리전 환경에서 CloudFront Functions로 사용자 위치 기반 원본 서버 리다이렉션을 구현하여 응답 속도와 사용자 경험 개선
아키텍처
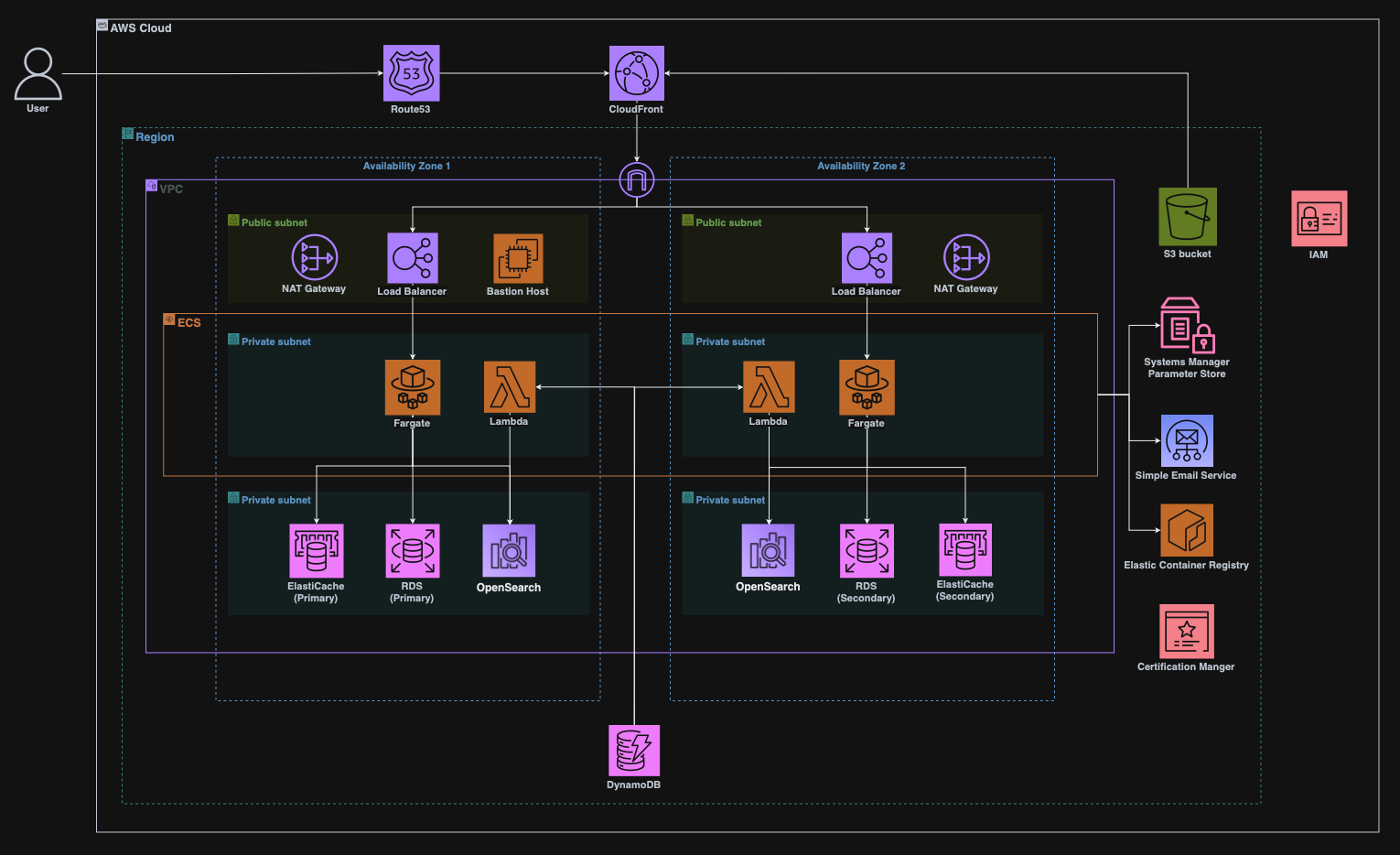
구현 및 설계 상세 내용
1. 쓰기-읽기 분리를 통한 마이크로서비스 아키텍처 개선 및 CQRS 적용
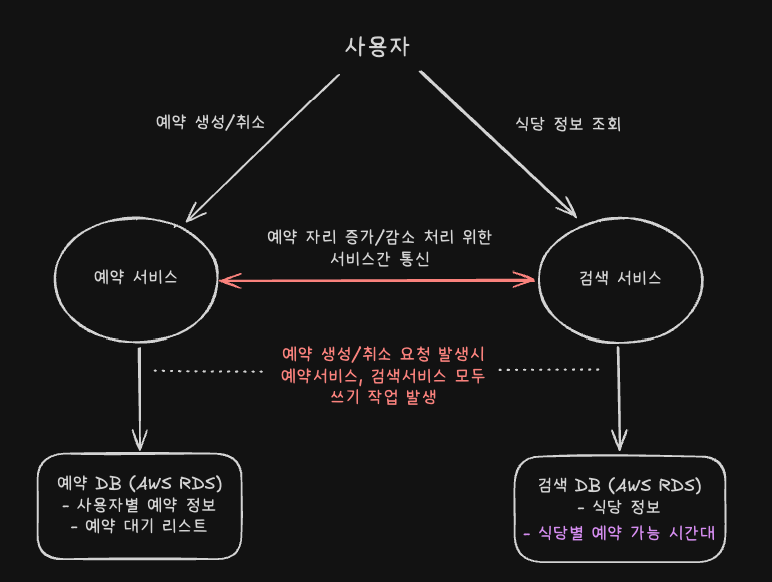
프로젝트 초기에는 예약 서비스와 검색 서비스를 별도의 마이크로서비스로 구성하였고, 각 서비스마다 RDB를 두어 다음과 같은 역할을 갖도록 했습니다.
- 예약 서비스
- 사용자별 예약 정보, 예약 대기 리스트 관리 (쓰기 위주)
- 검색 서비스
- 식당 정보 및 식당별 예약 가능 시간대 관리 (주로 읽기, 그러나 예약 생성·취소 시 쓰기 작업 필요)
초기 설계의 문제점
- 서비스 간 높은 결합도
- 예약 생성 또는 취소 시, 예약 서비스가 검색 서비스의 API를 호출하여 해당 예약에 대한 식당별 예약 가능 시간의 자리를 증/감시키는 별도의 쓰기 작업을 수행해야 했습니다. 이는 예약 서비스와 검색 서비스 간의 의존도를 높였고, 시스템 복잡도를 증가시켰습니다.
- 검색 서비스의 잦은 쓰기 작업 부담
- 본래 검색 서비스는 주로 읽기(조회) 요청에 최적화되어야 하나, 예약 관련 변경사항 반영을 위해 쓰기 작업이 빈번히 발생하였습니다. 이는 검색 성능과 확장성 측면에서 비효율적이었습니다.
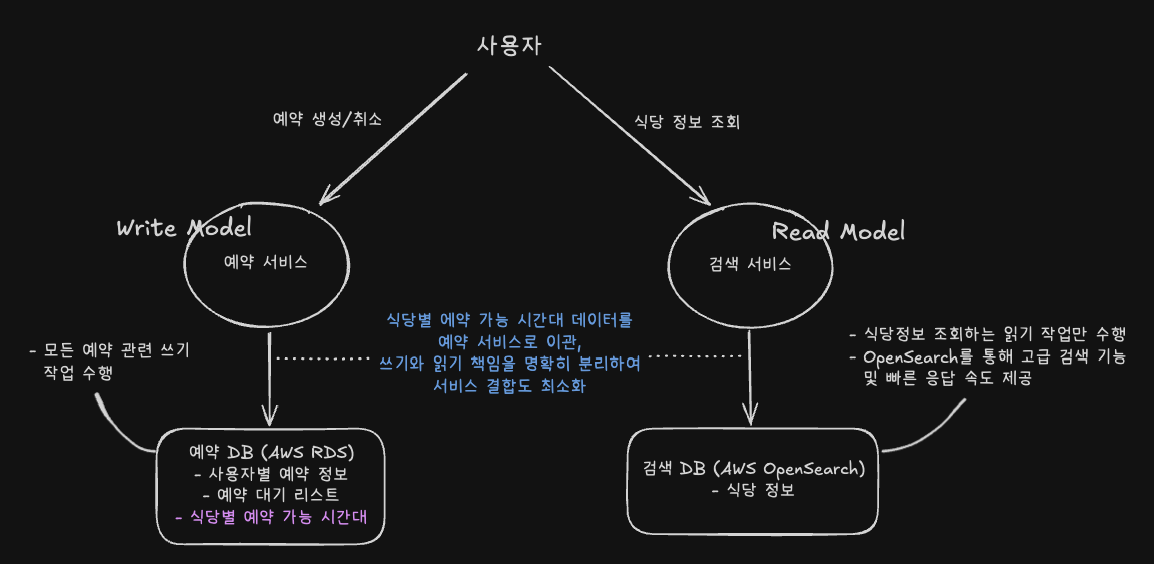
개선 방안
해당 문제 해결을 위해 쓰기(Write)와 읽기(Read) 책임을 명확히 분리하는 방향으로 아키텍처를 개선하였습니다.
- 명확한 쓰기 책임 부여: 예약 서비스
- 식당별 예약 가능 시간대 데이터를 예약 서비스로 이관하여, 예약 생성·취소 등 모든 상태 변경 로직과 쓰기 작업을 예약 서비스 한 곳에서 처리하도록 하였습니다.
- 읽기 전용 역할 강화: 검색 서비스
- 검색 서비스에는 식당의 기본 정보만 유지하고, OpenSearch 고성능 검색 솔루션을 활용해 고급 조회 기능과 빠른 응답 속도를 제공하도록 하였습니다. 이로써 검색 서비스는 본래 목적에 집중하여 최적화된 읽기 전용 서비스로 기능하게 되었습니다.
결과
- 서비스 간 결합도 감소
- 예약 서비스 내에서 모든 쓰기 로직을 처리함으로써, 더 이상 예약 서비스와 검색 서비스 간의 API 호출을 통한 데이터 동기화가 필요 없어졌습니다.
- 읽기/쓰기 모델 분리 (CQRS 구현)
- 쓰기 모델(예약 서비스)과 읽기 모델(검색 서비스)을 분리함으로써 CQRS 패턴을 적용한 사례로 볼 수 있습니다. 이로써 각 서비스는 자신의 기능에 특화된 최적화 전략을 수립할 수 있었습니다.
💡 CQRS(Command Query Responsibility Segregation)
CQRS는 명령(Command, 쓰기)와 조회(Query, 읽기) 로직을 분리하는 패턴
2. AWS 기반 MSA 설계와 데이터베이스 최적화
해당 프로젝트의 서비스 특성상 예약 기능과 검색 기능에 많은 트래픽이 몰릴 것으로 예상하였고, 해당 서비스만 유연하게 확장하고 유지보수를 용이하게 하기 위해 마이크로서비스 아키텍처를 도입하였습니다.
또한, 분리된 각 서비스를 독립된 컨테이너로 구성하여 AWS ECS를 통해 배포 및 운영함으로써, 서비스의 확장성과 유연성을 확보하고 안정적인 운영을 구현하였습니다.
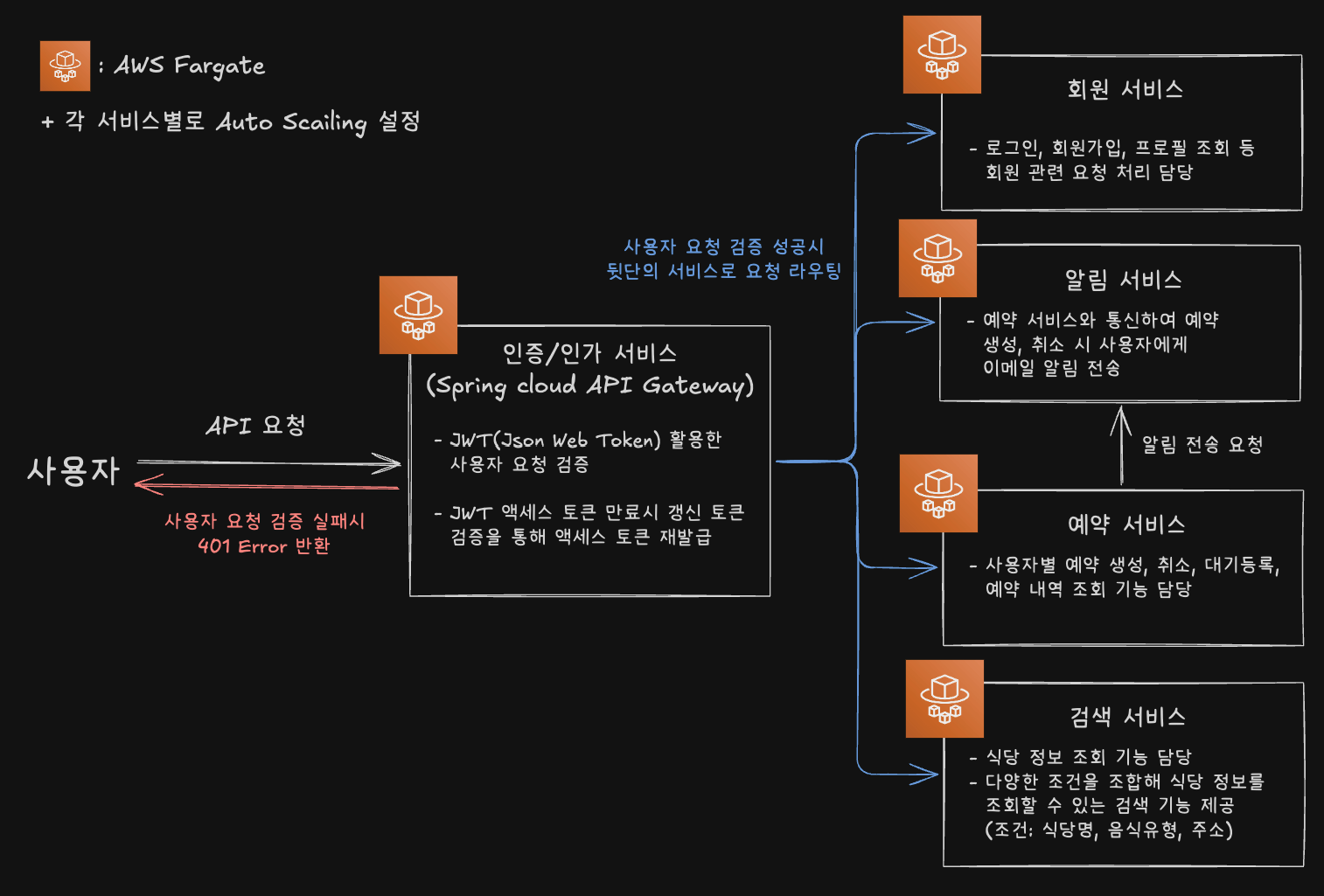
다음으로, 각 서비스의 요구사항에 맞춰 최적의 데이터베이스를 선택하여 읽기/쓰기 성능을 최적화 하였습니다.
| 연결 서비스 | ||||
|---|---|---|---|---|
| 회원 DB | 회원 정보는 스키마가 보다 명확하며 데이터 무결성이 매우 중요 | AWS RDS | 데이터 무결성이 중요한 회원 정보를 안전하고 신뢰성 있게 관리하기 위해 AWS RDS 선택 | 회원 서비스 |
| 예약 DB | 예약 생성, 취소, 업데이트 등 쓰기 작업이 빈번하고 중복 예약과 오버부킹 방지를 위해 데이터 무결성 및 정합성이 매우 중요 | AWS RDS | 예약 시 빈번한 쓰기 작업과 데이터 정합성을 보장하기 위해 트랜잭션이 가능한 AWS RDS 선택 | 예약 서비스 |
| JWT 관리 | 토큰 검증 및 조회 작업이 매우 빈번하며 토큰의 만료시간 관리가 필요 | AWS ElastiCache | 메모리 기반 빠른 성능과 TTL(Time-to-Live) 기능을 제공하는 AWS ElastiCache 선택 | 회원 서비스, 인증/인가 서비스 |
| 검색 DB | 검색은 읽기 작업이 많고 빠른 응답이 필수적이며, 사용자가 다양한 조건으로 정확하고 빠른 검색을 원함 | AWS OpenSearch | 빠른 읽기 성능과 고급 검색 기능 제공을 위해 AWS OpenSearch 선택 | 검색 서비스 |
초기 설계의 문제점
초기 설계에서는 식당 데이터를 OpenSearch에만 저장하여 이를 영구 저장소로 활용했습니다. 그러나 OpenSearch는 빠른 검색과 분석에는 최적화되어 있지만, 데이터 일관성과 장애 복구 기능이 제한적이므로 영구 저장소로 사용하기에는 부적합하다는 한계가 있었습니다.

개선 방안
이 문제를 개선하기 위해 DynamoDB를 영구 저장소로 선택하고, DynamoDB Streams와 Lambda를 활용해 변경된 데이터를 OpenSearch로 실시간 동기화하는 구조를 설계했습니다. 이를 통해 사용자에게 최신 데이터를 빠르게 제공하면서 데이터 이중화와 안정성을 동시에 확보했습니다.
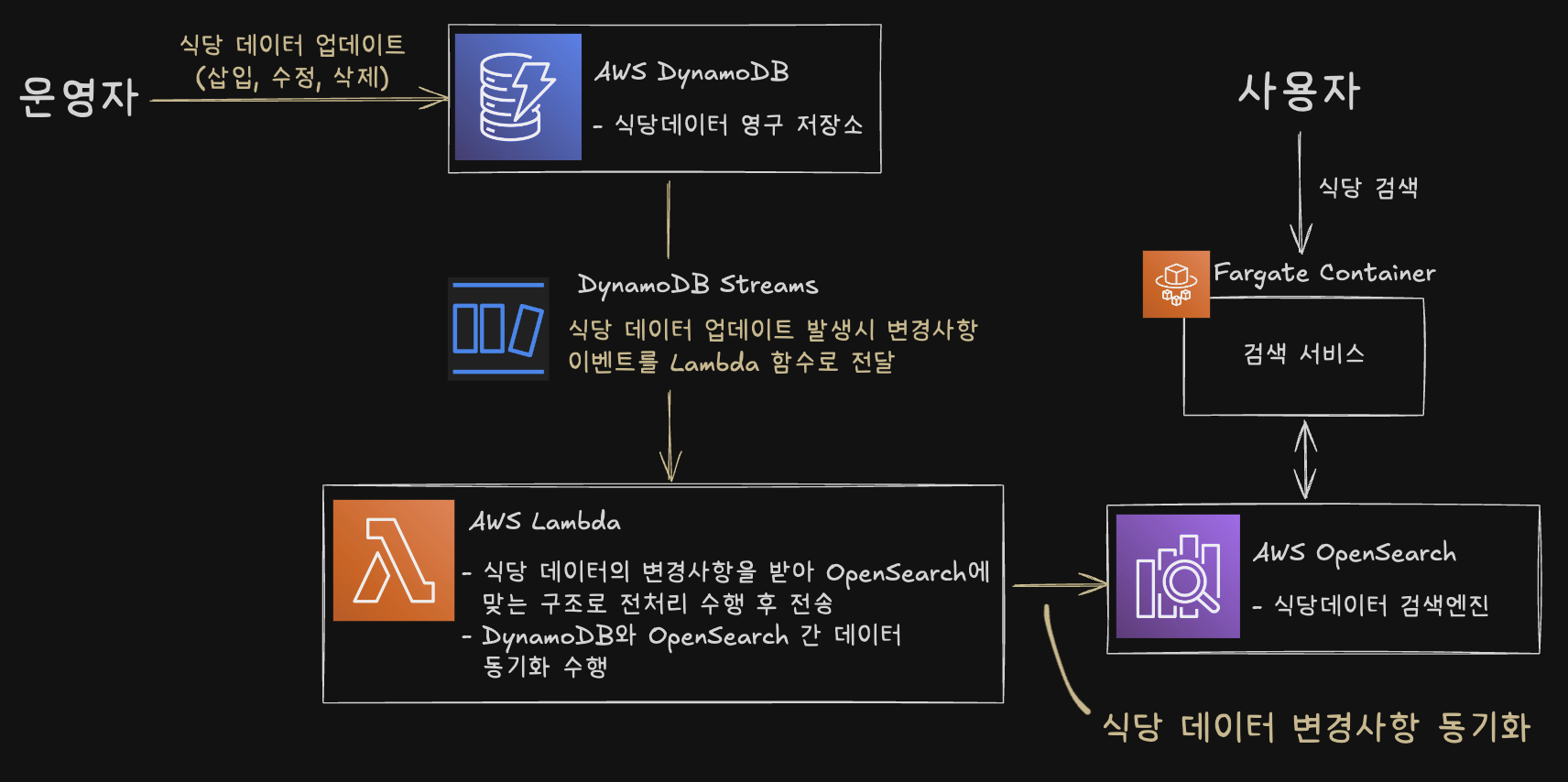
결과
- 마이크로서비스 아키텍처 기반 확장성과 관리 효율성 확보
- 예약, 검색, 인증/인가, 회원, 알림 서비스 등 5개의 마이크로서비스를 AWS ECS Fargate에 각각 독립된 컨테이너로 배포하여 각 서비스가 개별적으로 확장 및 관리되도록 설계했습니다.
- 데이터 이중화 및 실시간 동기화 구현
- DynamoDB를 영구 저장소로 사용하고, DynamoDB Streams와 Lambda를 통해 OpenSearch와 실시간 동기화를 구현함으로써, 데이터 이중화와 안정성을 확보하고 최신 데이터를 빠르게 제공할 수 있는 시스템을 구축했습니다.
3. CloudFront Functions를 활용한 사용자 위치 기반 리다이렉션
초기 설계에서는 사용자가 접속한 위치에 따라 가장 가까운 리전으로 트래픽을 유도하기 위해 Route53 지리적 라우팅을 선택했습니다. 이 방식은 초기 설정이 간단하고 관리가 용이하다는 장점이 있지만, 사용자가 특정 리전의 서비스를 선택할 경우 프론트엔드에 별도의 도메인 관리 로직을 구현해야 하는 단점이 있습니다. 이러한 추가 로직은 유지보수 비용과 개발 복잡도를 증가시키며, 프로젝트 기간 내에 완료하기 어렵다고 판단되었습니다.
| 서비스 | 장점 | 단점 |
|---|---|---|
| Route53 지리적 라우팅 | DNS 레벨에서 지리적 라우팅을 손쉽게 구성할 수 있어 초기 설정이 간단 | 사용자가 특정 리전을 선택할 때 프론트엔드에 별도 도메인 관리 로직이 필요하여 유지보수 및 개발 복잡도가 증가함 |
| CloudFront Functions | 엣지 레벨에서 국가별 리다이렉션을 가볍고 빠르게 처리할 수 있어 프론트엔드 복잡도를 낮추고 지연시간을 최소화 | Lambda@Edge보다 기능 범위가 제한되어 복잡한 로직 구현에는 제약사항 |
| Lambda@Edge | 엣지 레벨에서 복잡한 로직을 구현할 수 있어 다양한 요청 변환 및 고급 처리에 유연 | CloudFront Functions 대비 무겁고 비용, 지연시간이 증가하기 때문에 단순한 국가별 라우팅에는 과도한 선택일 수 있음 --- 요금(요청 백만 회당): CF Functions $0.1, Lambda@Edge $0.6 |
최종 선택
이러한 비교를 바탕으로, CloudFront Functions를 도입했습니다. CloudFront Functions는 요청 시 사용자 국가 코드를 확인해 해당 국가에 가장 가까운 리전으로 즉시 리다이렉트하는 경량 서버리스 기능입니다. 이를 통해 프론트엔드 측 수정 부담을 크게 줄이면서 국가별 라우팅을 구현할 수 있었고, 단순한 로직으로도 글로벌 사용자 경험을 개선할 수 있었습니다.
도입 효과
- 사용자 위치 기반 자동 라우팅
- CloudFront의
cloudfront-viewer-country헤더를 활용하여 사용자의 접속 국가를 판단하고, 해당 국가에 맞는 최적의 리전으로 자동 라우팅하는 로직을 구현하였습니다. - 사용자가 다른 국가의 리전을 선택하는 경우
x-region헤더에 선택한 국가의 국가 코드값을 설정하고x-region에 값이 설정되어 있는 경우 해당 값을 우선 적용하여 사용자가 원하는 국가 리전의 서비스를 이용할 수 있도록 해주었습니다.
- CloudFront의

- 지연 시간 최소화
- 사용자가 인접한 리전으로 즉각 연결되므로, 네트워크 왕복 지연이 감소하여 응답 속도가 빨라졌고, 전반적인 사용자 경험이 향상되었습니다.
- 사용자가 인접한 리전으로 즉각 연결되므로, 네트워크 왕복 지연이 감소하여 응답 속도가 빨라졌고, 전반적인 사용자 경험이 향상되었습니다.
- 운영 관리 비용 절감
- 새로운 리전을 추가하거나 기존 라우팅 정책을 조정할 때도 CloudFront Functions 스크립트만 수정하면 되므로, 글로벌 서비스 확장 시 발생하는 관리 부담이 크게 줄어들었습니다.
결과
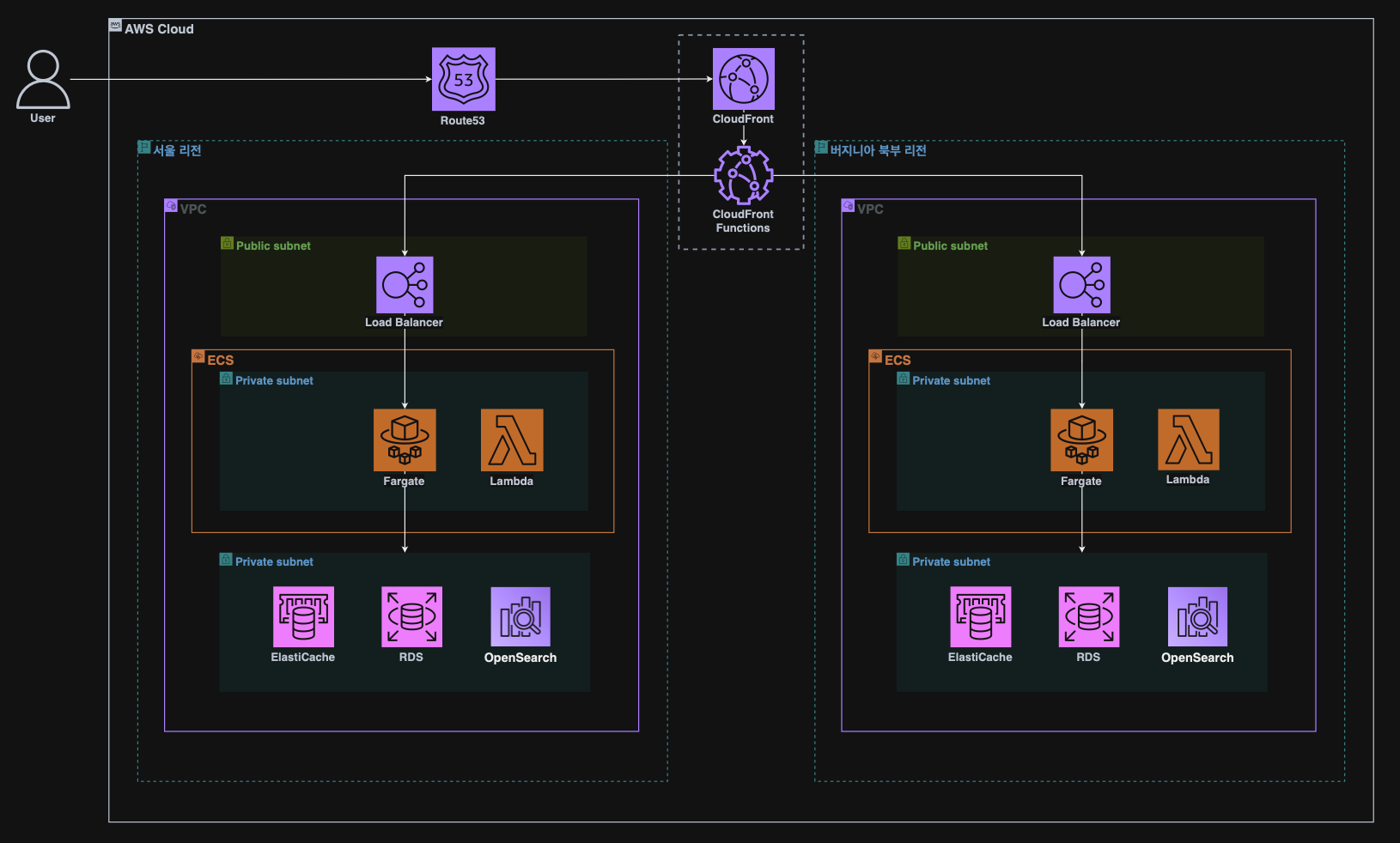
-
CloudFront Functions를 적용했을때 멀티 리전 아키텍처입니다. 사용자가 API 요청을 보내면 CloudFront Functions 스크립트가 실행되어 사용자와 가장 가까운 리전의 ALB(Application Load Balancer) 또는 사용자가 선택한 리전의 ALB로 요청을 리다이렉트합니다.
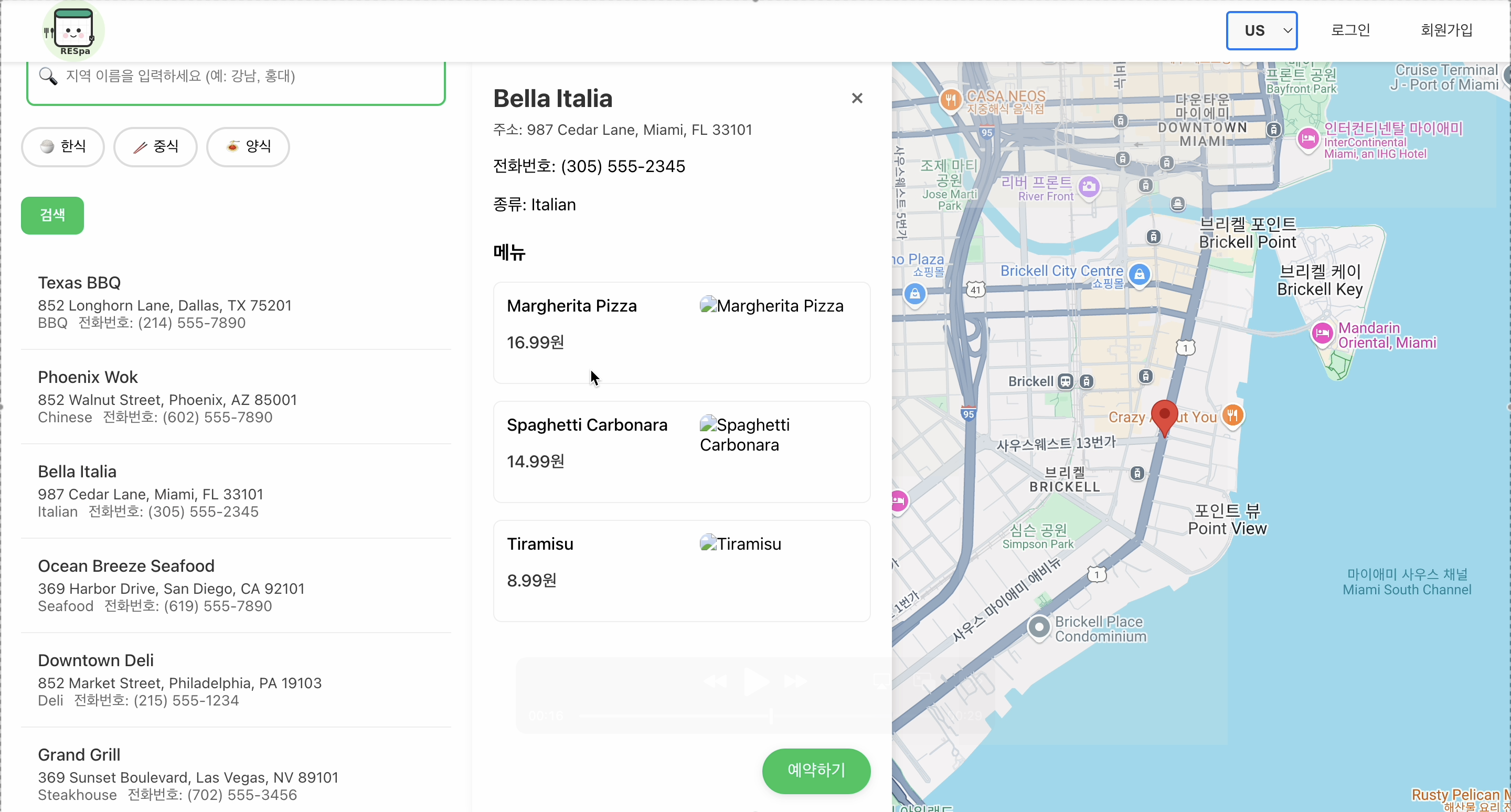
-
드롭다운 메뉴에서 미국(버지니아 북부) 리전 선택시 미국 식당이 검색되는 것을 확인할 수 있습니다.
결과
- 확장 가능하고 안정적인 서비스 구축
- 서비스를 MSA 로 설계하고 AWS ECS로 배포함으로써 보다 유연하게 확장 가능하고 안정적인 서비스 환경을 조성했습니다.
- 글로벌 사용자 대상 지연 시간 최소화
- CloudFront Functions로 사용자 위치 기반 리다이렉션을 구현해 가장 가까운 리전으로 트래픽을 유도하여 응답 속도와 서비스 가용성을 향상시켰습니다.
- 데이터 일관성과 운영 효율성 확보
- DynamoDB Streams - Lambda - OpenSearch 구조로 데이터 변경의 실시간 반영과 자동 데이터 동기화를 구현했습니다.
성과
- 교보CDA 1회차 프로젝트 경진대회 최우수상 수상